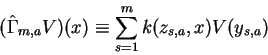Reinforcement Learning is concerned with optimal control in Markov Decision Process (MDP) in cases where the transition model is unknown. One possibility is to estimate the value function of the system using training data. We suggest to carry out this estimation nonparametrically using kernel smoothers. By contrast to the widely known ``temporal difference'' training of neural networks, algorithms based on this nonparametric approach can be proven to converge to a unique fixed point. Furthermore, asymptotic theory can be used to bound the approximation error and to shed light on the bias-variance tradeoff in reinforcement learning.
We consider a MDP defined by a filtered probability space
![]() ,
a cost function c(x,a), as well as
sequences
of states and actions,
,
a cost function c(x,a), as well as
sequences
of states and actions,
![]() and
and
![]() ,
respectively.
The objective is to find a policy
,
respectively.
The objective is to find a policy ![]() - a mapping from states into actions -
that minimizes one of several cost criteria.
As an example, we consider the infinite-horizon
- a mapping from states into actions -
that minimizes one of several cost criteria.
As an example, we consider the infinite-horizon ![]() -discounted
expected cost
-discounted
expected cost
The approximate operator (8) allows for
an efficient implementation and a detailed theoretical analysis:
First, we show that approximate value iteration using (8) leads to a unique fixed point, ![]() .
Second, we derive the asymptotic distribution of
.
Second, we derive the asymptotic distribution of ![]() that
can be used to establish the convergence rate
that
can be used to establish the convergence rate
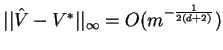 .
In addition, the asymptotic distribution of
.
In addition, the asymptotic distribution of ![]() allows for an analysis of the bias-variance tradeoff in reinforcement learning. In detail, we argue that value function estimates
are typically biased downwards regardless of the learning algorithm.
This bias is due to Jensen's inequality and the convexity of the minimum operator.
Using the asymptotic distribution of (8),
we derive analytic expressions to assess the quantity of the bias
for the case of kernel-based reinforcement learning.
In principle, these expressions can be used for
bias correction. A simple example problem using simulated financial time-series data
demonstrates the practical virtues of the new algorithm.
allows for an analysis of the bias-variance tradeoff in reinforcement learning. In detail, we argue that value function estimates
are typically biased downwards regardless of the learning algorithm.
This bias is due to Jensen's inequality and the convexity of the minimum operator.
Using the asymptotic distribution of (8),
we derive analytic expressions to assess the quantity of the bias
for the case of kernel-based reinforcement learning.
In principle, these expressions can be used for
bias correction. A simple example problem using simulated financial time-series data
demonstrates the practical virtues of the new algorithm.
![\begin{displaymath}V_\mu(x) \equiv \lim_{T\rightarrow \infty} E^\mu_x
\left[ \frac{1}{T} \sum_{t=0}^{T-1} \alpha^{T-t} c(X_t,\mu(X_t)) \right].
\end{displaymath}](img26.gif)