


Next: Über dieses Dokument ...
Up: No Title
Previous: Kernel-Based Reinforcement Learning
Neural networks have been applied to a variety of information processing tasks, including classification, regression, and reinforcement learning.
In many practical applications, however, focus is on alternative aspects of a data-generating process. For example,
in financial time-series analysis, higher-order statistics such as the variance, skewness,
and kurtosis are typically of interest.
One possibility to obtain such information is by modeling the
probability distribution characterizing the data source explicitly.
In my thesis, I demonstrate that neural networks
- interpreted loosely as flexible parametric models -
can be very efficient models of probability distributions.
Focus is on the analysis of non-linear time-series and cross-sectional data.
Univariate Density Estimation
To derive a neural network model for time-series data, I first consider continuous univariate distributions. Focus is on the modeling of skewness and kurtosis.
These properties are of central importance for many financial forecasting tasks including derivatives pricing and risk analysis.
I compare three approaches:
- 1.
- Maximum Entropy Distribution
Given specific restrictions imposed by the data,
an information-theoretic approach to density estimation
is to choose that model which maximizes the entropy. For example, using the first four sample moments
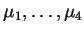 as restrictions, we
obtain an exponential family model of the form:
as restrictions, we
obtain an exponential family model of the form:
![\begin{displaymath}f^{ME}(x\vert\lambda_1,\lambda_2,\lambda_3,\lambda_4) \equiv ...
...\lambda_1 x +
\lambda_2 x^2 + \lambda_3 x^3 + \lambda_4 x^4]}.
\end{displaymath}](img37.gif) |
(10) |
A serious concern is the computation of density parameters
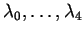 that fit the observed moments
.
Mathematically, we face the task to solve a multivariate nonlinear equation system.
I develop a numerically stable algorithm that computes the density parameters efficiently.
that fit the observed moments
.
Mathematically, we face the task to solve a multivariate nonlinear equation system.
I develop a numerically stable algorithm that computes the density parameters efficiently.
- 2.
- Gram-Charlier Density
As a second approach,
I consider a truncated Gram-Charlier series expansion of the
unknown density.
Specifically, I consider models of the form
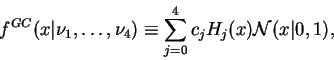 |
(11) |
where
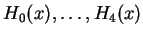 correspond to the first five Tschebycheff-Hermite polynomials.
A major advantage of model (10) is its suitability for neural network training. Because (10) can be written alternatively in terms of unrestricted factors, it is well-suited for the combination with a neural network to predict the density parameters.
correspond to the first five Tschebycheff-Hermite polynomials.
A major advantage of model (10) is its suitability for neural network training. Because (10) can be written alternatively in terms of unrestricted factors, it is well-suited for the combination with a neural network to predict the density parameters.
Conditional Density Estimation
I consider a nonlinear extension of ARCH-/GARCH-type models for financial time
series identification.
Specifically, focus is both on the identification of nonlinear dependencies and on the modeling of conditional skewness and kurtosis of the time-series.
As a conditional density model,
I use the Gram-Charlier expansion (10)
where the density parameters are predicted by means of a neural network.
In particular, the parametrization of the density model is chosen so that, first,
the conditional density is well-defined regardless of
the neural network outputs, and second, gradients for neural network training can be evaluated easily. Experiments using real stock market data give an performance improvement by comparison to several ARCH-/GARCH-type models.
Multivariate Density Estimation
Finally, I consider the case of mutivariate, cross-sectional data.
As a density model I use Gaussian mixtures trained with the EM algorithm.
It is well-known that unregularized density estimation using
Gaussian mixtures may well lead to overfitting: In the extreme case, the log-likelihood can go to infinity if the center of one Gaussian coincides with one of the data points and its variance approaches the null-matrix (see Figure 2, left). I compare three alternatives to deal with this situation:
- 1.
- Averaging
Averaging can improve the performance of a predictor if the individual models are sufficiently diverse. I compare several resampling schemes to increase diversity including bagging.
- 2.
- Maximum Penalized Likelihood
An alternative approach is to add a penalty term to the log-likelihood function as a
regularizer. The maximum penalized likelihood approach is equivalent
to the maximum a posterior (MAP) parameter estimate in a Bayesian approach
if we interpret the penalty as the negative logarithm of the prior distribution.
In particular, if we choose the negative logarithm of a conjugate prior
as the penalty function,
we can derive EM update rules to obtain
the optimal parameter estimates.
Regularized density estimates using several hyper-parameters are shown in Figure 2 (middle and right).
- 3.
- Bayesian Sampling
In a ``fully'' Bayesian approach we compute the predictive distribution by integrating with respect to the posterior
distribution.
We use a Markov Chain Monte Carlo (MCMC) method for this purpose.
In detail, parameter values can be sampled hierarchically using ``data augmentation'' in the Gaussian mixture case.
Abbildung:
Unregularized density
estimate (left) and regularized density estimates based on a Gaussian mixture
with 40 components
(middle:
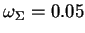 ,
right:
,
right:
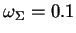 ).
).
figure=cir_g0_01.eps,width=
figure=cir_g0_05.eps,width=
figure=cir_g0_1.eps,width=
|
Experiments using artificially generated and real-world medical data give that
averaging and
maximum penalized likelihood always performed better than the
maximum likelihood approach. The Bayesian approach gave good
performance on a low-dimensional toy data set but failed on two
higher-dimensional problems with ten and six
dimensions, respectively.
Averaging clearly outperformed maximum penalized likelihood on the medical data set.
Next: Über dieses Dokument ...
Up: No Title
Previous: Kernel-Based Reinforcement Learning
Dirk Ormoneit
1999-10-17